
Язык XML и Семантическая Сеть
Оригинал: XML and the Semantic Web (pdf)
James Hendler & Bijan Parsia
Пришло время прекратить эти споры — что якобы они не совместимы
За последние пару лет прогресс на пути построения Семантической Сети уверенно набирает обороты. Всевозможные публикации, начиная от научно-популярной прессы и заканчивая известными научными изданиями, описывают захватывающие возможности Семантической Сети, благодаря которым она превзойдёт существующую Сеть. В данной статье мы попробуем дать представление о том, что же такое Семантическая Сеть, а главное — постараемся развеять распространённый миф о том, что якобы язык XML и Семантическая Сеть — вещи несколько несовместимые.
Форматы, основанные на языке XML, становятся преобладающими средствами для разметки данных в Сети. Уже имеются стандартные XML-языки для гипертекста (XHTML), графики (SVG), синдикации [сбора и обобщения информации] (RSS), мультимедиа (SMIL), описания и обнаружения сервисов (WSDL и UDDI), а также много других форматов, не говоря уже о многочисленных, зачастую кустарных [ad hoc], узко специализированных XML-языков. [Здесь и далее ссылки переводчика; ссылки авторов даны ими в виде явного указания URL в тексте статьи.]
Более того, существуют стандартные средства формирования запросов (XPath и XQuery), связывания (XLink и XPointer), а также синтаксического анализа [parse] и программирования (SAX и DOM) под XML-документы. Наконец, можно осуществлять интеграцию с другими XML-форматами достаточно прямолинейно путём включений (используя пространства имён XML) или преобразований (используя XSLT).
Язык XML как механизм обмена
Учитывая эти факты, трудно оспаривать XML как механизм обмена в Сети. Однако модель XML порождается главным образом самими документами; более точно — текстовыми документами с иерархической структурой. Например, правильно составленный XML-документ может иметь элемент
Однако фактически такая схема не позволяет уловить бóльшую часть семантики понятия «адрес». Например, если мы встретим несколько отдельных документов, в которых указаны адреса, совпадающие полностью за исключением почтового индекса, то мы не сможем распознать, основываясь лишь на описанной схеме, что по меньшей мере один из этих индексов является ошибочным. Аналогично, не существует способа задать автоматическое преобразование между двумя очень похожими схемами кодирования адреса (например, если в одной из схем имеется ровно один элемент
Ещё более удручающим является то, что не существует очевидного способа связать наши данные в
Тогда как в Сети нам крайне важна такого рода семантика. Мы хотим уметь привязывать [connect] адреса, закодированные с помощью языка XML в некотом веб-документе, к конкретным людям, местоположениям, понятиям, письмам, другим документам, базам данных, справочникам, спискам адресатов в электронной записной книжке PDA, календарям, сенсорам, услугам и всевозможным другим ресурсам в Сети. Если всё это сделать правильно, то такие связки [links] позволят автоматически обрабатывать информацию, хранящуюся в различных формах и форматах, с помощью компьютерных программ. Безусловно, язык XML является важной составляющей для решения этих проблем, но маловероятно, что XML-модель данных способна подходящим [feasible] образом представить все эти взаимосвязи и закодированную в них семантику реального мира.
Моделирование связей
Понаблюдав за тем, как работают ссылки в существующей Сети, можно понять, что требуется для их моделирования. Веб-ссылки имеют два ключевых аспекта: во-первых, ресурсы [things] в Сети однозначным образом адресуются [identify] посредством URI (Uniform Resourse Identifiers — Единообразных Идентификаторов Ресурсов). Во-вторых, всякая веб-ссылка имеет следующую трёхчастную структуру:
- Ресурс, из которого мы ссылаемся (источник ссылки). (В языке XHTML им является файл, содержащий тэг /a/ с атрибутом href.)
- Соединительный [connecting], или связующий [linking], бит между источником и целевым объектом ссылки.
- Ресурс, в который мы прибываем по ссылке (цель [target]). (В языке XHTML обычно задаётся посредством URI-идентификатора в значении атрибута href.)
И хотя, разумеется, можно закодировать веб-ссылку в языке XML (например, чем-нибудь вроде /a href="..."/), обратите внимание, как мало общего между веб-ссылками и XML-моделью данных: веб-ссылки используют URI-идентификаторы вместо тэгов или QNames; в отличие от XML, веб-ссылки не задают ни какой бы то ни было внутренней иерархии, ни понятия «одно содержится в другом» [containment], ни какого-либо упорядочения объектов, фигурирующих в ссылках. И на самом деле, совокупрость веб-ссылок совершенно не похожа на дерево Объектной Модели Документа (DOM), а скорее уж очень напоминает RDF-граф (RDF — Resource Description Framework — Система Описания Ресурсов), так что каждая ссылка отвечает некоторому RDF-триплету. Стоит сказать также, что каждая часть RDF-триплета может быть задана, а чаще всего и задаётся, с помощью URI-идентификатора, а также что триплет, несомненно, обладает трёхчастной структурой.
Эти три части триплета, по своей задумке, в точности соответствуют частям, из которых состоят веб-ссылки:
- Субъект триплета — это то, откуда мы стартуем.
- Предикат связывает субъект с объектом.
- Объект отвечает цели [target] веб-ссылки.
И RDF-триплет действительно является представлением веб-ссылок, в котором каждая часть ссылки уже задана в явном виде. Таким образом, совокупность RDF-триплетов — это одно из возможных средств для представления, совместного использования [share] и обработки значительной части структуры Сети как таковой. Стандартизированное представление Сети позволяет нам обогатить семантику не просто информацией, содержащейся в документах Сети, но также и информацией, выражаемой самой структурой Сети. Каждая веб-ссылка сама по себе — это весьма неясное, зачастую неоднозначное и практически всегда не полностью сформулированное [underspecified] утверждение о ресурсах [things], которые она связывает. RDF же позволяет устранить подобного рода неясности и исключить какие-либо неоднозначности. RDF-Схема (RDFS) и недавно появившийся Язык Сетевых Онтологий (Web Ontology Language, OWL, читается [áул] — Прим.перев.) позволяют точно моделировать смысл подобных утверждений-ссылок в виде, пригодном для машинной обработки.
RDFS является достаточно простым языком для создания сетевых [Web-based] «настраиваемых словарей» [controlled vocabularies] и таксономий. Этот язык позволяет задать несколько RDF-предикатов, с помощью которых можно будет описывать связи между понятиями. Более того, он позволяет определять классы и свойства-отношения между ними, а также в нём имеются механизмы для ограничения области определения [domain] и области значений [range] этих отношений. Например, в RDFS можно создать категории веб-сайтов наподобие Yahoo-классификации, представив их в виде иерархии классов с наборами именованных (иногда наследуемых) свойств. Это позволяет другим сайтам привязывать содержащуюся на них информацию к этим терминам, что даёт более широкие возможности для взаимодействия в сфере B2C- и B2B-приложений, а также других веб-транзакций. [Прим.перев.: B2C (business-to-consumer, бизнес для потребителя) и B2B (business-to-business, бизнес для бизнеса) — типы интернет-ресурсов, ориентированных на осуществление операций и поддержку отношений между компаниями и клиентами (B2C) и между компаниями (B2B) соответственно.]
Язык OWL (Web Ontology Language — Язык Сетевых Онтологий) является дальнейшим обогащением RDFS, которое уже пригодно для создания тезаурусов и моделирования различных предметных областей. OWL базируется на веб-языке DAML+OIL, разработанном совместно Агентством перспективных оборонных исследовательских проектов США (DARPA — Defense Advanced Research Projects Agency) и Программой по Информатизации и Технологиям Евросоюза (EU IST — European Union’s Information Science and Technology program). DAML+OIL стал активно использоваться в правительстве, а в ноябре 2001 года WWW-Консорциумом (W3C) была образована рабочая группа по Сетевым Онтологиям (Web Ontology Working Group), которая усовершенствовала DAML+OIL, что привело к появлению официально рекомендованного Консорциумом языка, получившего название OWL.
Язык OWL расширяет RDFS множеством конструкций для определения отношений между классами, а главное — он позволяет налагать ограничения на свойства (они же предикаты), используемые для связывания элементов (entities). Тем самым OWL даёт возможность пользователям описывать простые модели их предметных областей, пользуясь этими предикатами и наложенными на них ограничениями. Детальное обсуждение этого языка выходит за рамки данной статьи (подробнее с ним можно ознакомиться по адресу www.w3.org/2001/sw/WebOnt), однако, имея уже OWL в арсенале, полезно ещё раз вернуться к нашему примеру с адресами, чтобы прояснить некоторые моменты.
XML и OWL
В языке XML можно было выразить лишь, что в нашем документе присутствует поле
Помимо этого онтологии позволяют устанавливать более точные связи с другими документами и ресурсами, основываясь на совместном использовании понятийных терминов, даже в случае, если имеется лишь частичное соответствие терминов (в этом ключевое отличие от XML-подхода). Ввиду этого нашу базу знаний об адресах можно связать с другими системами терминов — зная, например, что адреса суть имена неких местоположений [location], мы можем связать наши знания об адресах с другими веб-ресурсами, так или иначе имеющими дело с описаниями местоположений. Ими могут быть базы данных или веб-сервисы, подав которым на вход некий адрес, можно получить на выходе местонахождение ближайшего аэропорта (ещё одна разновидность местоположений) или прогноз погоды для города, в котором находится данный адрес, или же другие территориально-зависимые данные. Метаданные также можно использовать для привязки к онтологиям какой-либо нетекстовой информации, например, что на некой фотографии изображён дом, расположенный по определённому адресу, или же что действие, описанное в каком-либо видео-материале, происходит в определённом штате (позволяя Вам сравнить это местонахождение с Вашим и понять, могли ли происходить описанные там события, исходя из расположения других участвующих в действии объектов и ограничений относительно них).
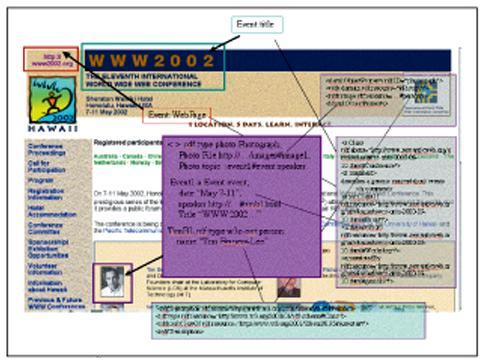
На рисунке изображён пример привязки некоторого веб-сайта к онтологической информации. В этом примере, взятом из презентации по OWL, представленной на W3C-сессии Конференции по Всемирной Компьютерной Сети в мае 2002 г., информация об основном докладчике связывается с информацией о событиях, фотографиях и других людях.
Наш пример с адресами — чрезвычайно упрощён, и тем не менее уже видно гигантское число возможных его применений. Переформулировка неявной семантики, заложенной в XML DTD и в схемы, в терминах явно выраженных в RDFS и OWL отношений, позволит легко реализовать широкий спектр новых приложений, по большей части произрастающих из установления связей между веб-ресурсами. В сфере бизнеса подобного рода привязку к моделям можно будет применить к задачам хранения данных SEC [Security Exchange Commission — Комиссия по ценным бумагам], обслуживания баз данных о сети поставщиков [supply-chain], написания и публикации WSDL-описаний различных бизнес-услуг и к практически неограниченному переченю других приложений, что воплотит идею интеграции предприятий на общетевом [Web-wide] уровне. Текущие исследования в области Семантической Сети посвящены проблемам использования и расширения языков, основанных на RDF, для выражения таких понятий, как достоверность [trust] и авторизация, для автоматического обраружения и композиции веб-сервисов, а также проблемам разработки новых языков, которые позволят реализовать потенциал революционных возможностей Семантической Сети.
Семантическая Сеть строится на моделях, основанных на DRF-представлении веб-ссылок. Однако, для достижения максимального эффекта чрезвычайно важно связать эти тщательно продуманные модели, появившиеся благодаря Семантической Сети, с инструментами обработки документов и обмена данными путём распространения XML-технологий. Если бы XML- и RDF-технологии оказались несовместимыми, как некоторые полагают, то всё выше сказанное выглядело бы блефом [shame]. Но в действительности всё обстоит гораздо лучше. Хотя в основе их лежат несколько разные модели, нормативным форматом обмена RDF-, RDFS- и OWL-документами является именно XML. Таким образом, те, кто мыслят XML-категориями, могут смотреть на RDF, RDFS и OWL как на очередную серию языков, с которыми можно работать и управлять, используя стандартные инструменты. Приверженцы [purist] RDF могут увязать модели, порождаемые документами и структурами данных XML и XML-Схемы, с возможностью их совместной обработки [interoperable data]. Те же, кто сосредоточен на сфере веб-сервисов, будут видеть в технологиях SOAP и WSDL, сквозь их XML-содержимое, привычные RDF-модели, выражающие информацию, которую легко найти, связать и распознать.
Разумеется, как это обычно случается, когда несколько коллективов трудятся на частично перекрывающихся участках работы, существуют определённые трения между некоторыми членами RDF-сообщества и XML-общественности. Приверженцы RDF частенько сетуют на излишнюю (для них) запутанность XML. В свою очередь, XML-эксперты весьма недовольны тем, как RDF/XML-сериализация обходится с QNames и пространством XML-имён и трактует некоторые атрибуты и элементы-потомки как эквивалентные. Однако, подобные разногласия отнюдь не новы. На самом деле, они распространены и в самом XML-сообществе: стоит лишь напомнить, что некоторых XML-поклонников просто приводит в бешенство то, что XSLT обращается с QNames как с содержимым атрибутов. Аналогично, RDF-мир имеет массу тёмных и черезчур запутанных мест. Оба семейства языков до сих пор находятся в стадии развития, и кроме того для каждого из них разрабатываются также и не-XML-подобные синтаксисы (вспомним хотя бы
Лучший из лучших
В двух словах, Семантическая Сеть раскроет перед нами мир новых возможностей и произведёт функциональную революцию. Эти возможности будут нами обретены тем скорее, чем скорее мы прекратим спорить и осознаем, что разрыв между языками, основанными на XML и RDF соответственно, лежит где-то в области мелких технических различий, которые легко загладятся в процессе стандартизации или же устранятся с разработкой инструментов взаимодействия между ними. Возможность сочетать лучшие из этих языков и их разновидностей будет легко дарована нам посредством комбинирования «документов» XML-Сети и установления RDF-связей между ними. Добавьте к этому взаимодействующие друг с другом веб-сервисы — и картина станет захватывающей. Будущее Сети может стать более восхитительным, чем её прошлое, и объединив наши усилия и подходы, мы сможем быстрее в нём оказаться.
Полезные ссылки
- Программа «Семантическая Сеть» Консорциума W3C:
www.w3.org/2001/sw . - Спецификация языка RDF-Схема — черновой вариант:
www.w3.org/TR/rdf-schema . - «Интеграция приложений в Семантической Сети» (J.Hendler, T.Berners-Lee, and E.Miller; статья об использовании Семантической Сети в бизнес-приложениях):
www.w3.org/2002/07/swint . - Домашняя страница рабочей группы по Сетевой Онтологии консорциума W3C:
www.w3.org/2001/sw/WebOnt . - Краткий обзор основных хартеристик [feature synopsis] языков OWL-Lite и OWL — черновой вариант:
www.w3.org/TR/owl-features . - «Почему RDF-модель отличается от XML-модели» (T.Berners-Lee):
www.w3.org/DesignIssues/RDF-XML.html .
Об авторах
Jim Hendler — профессор университета в Мэриленде (Maryland), руководитель исследований в области Семантической Сети и технологий агентов в Мэрилендской Лаборатории Информации и Сетевой Динамики (Maryland Information and Network Dynamics Laboratory). Является членом Американской Ассоциации по искусственному интеллекту. Ранее — ведущий специалист [chief scientist] по информационным системам в Агентстве перспективных оборонных исследовательских проектов США (DARPA) и сопредседатель рабочей группы по Сетевой Онтологии консорциума W3C.
Bijan Parsia — исследователь в области Семантической Сети в Мэрилендской Лаборатории Информации и Сетевой Динамики (Maryland Information and Network Dynamics Laboratory). Научные интересы охватывают: инструменты работы с сетевыми логиками и правилами вывода, Семантические веб-сервисы, fine-grained, reflective annotation systems и trust-focused reasoning.
2 комментария:
разработки уроков разработка сайтов http://web-miheeff.ru разработки уроков
разработка управленческих решений разработка сайтов http://web-miheeff.ru разработка управленческих решений
Отправить комментарий